
Out of Distribution Adaptation in Offline RL via Causal Normalizing Flows
Published in Mathematics: Statistics and Operational Research, 2025
Abstract
Key Contributions
- Optimization framework: We propose a model architecture that uses a bijective CNFs for learning transition dynamics and a reward function and design a policy optimization framework where we use online policy optimization algorithm with OOD exploration.
- Improved performance: We showed that our algorithm outperforms existing model architecture with significant margin and robustness.
- Extensive ablation: We showed ablation studies how our framework is resilient to data quality, sophstication of algorithm (e.g., REINFORCE vs PPO), and include interpretable results on OOD predictive power using discrete environments.
🛠 Method Overview — MOOD-CRL
The core problem we tackle is how to leverage bijective causal normalizing flows (CNFs)—where input and output dimensions must strictly match—to predict transition dynamics and reward functions.
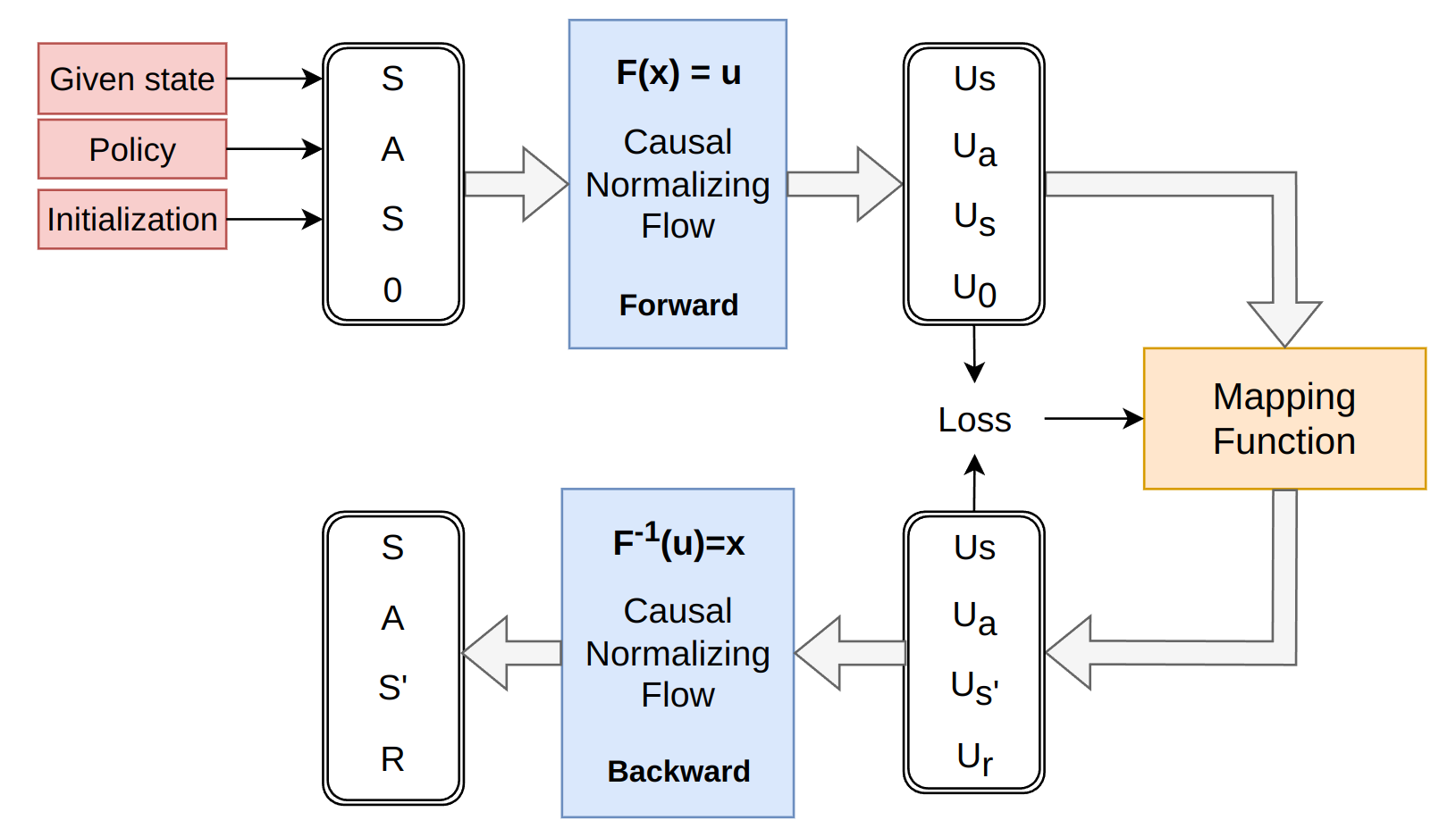
Figure 1: Architecture of the Causal Normalizing Flow for predicting next-state dynamics and rewards.
The challenge lies in the bijective constraint: to predict the next state \(s'\) and reward \(r\), the model theoretically requires an input of the same dimensionality. However, these values are exactly what we aim to estimate.
- Next State (\(s'\)): We provide the current state (\(s\)) as the input token, utilizing the inductive bias that \(s'\) is typically similar to \(s\) in continuous MDPs.
- Reward (\(r\)): We "void out" the reward input by setting it to zero to create a neutral starting token.
By training the CNFs to map this specific input (current state and zero-reward) to the ground-truth target (actual next state and actual reward) from the offline dataset, the flow learns to accurately model the underlying transition manifold while satisfying the bijective requirement.
📖 BibTeX Citation
@article{cho2025out,
title={Out of Distribution Adaptation in Offline RL via Causal Normalizing Flows},
author={Cho, Minjae and Sun, Chuangchuang},
journal={Mathematics},
volume={13},
number={23},
pages={3835},
year={2025},
publisher={MDPI}
}Recommended citation: Cho, M., & Sun, C. (2025). "Out of Distribution Adaptation in Offline RL via Causal Normalizing Flows." Mathematics, 13(23), 3835.
Download Paper