Intrinsic Reward Policy Optimization for Sparse-Reward Environments
📅 January 2026 📌 arXiv preprint arXiv:2601.21391
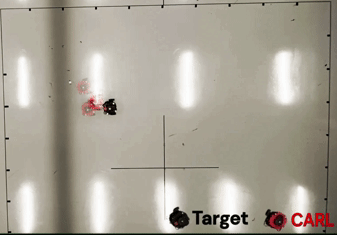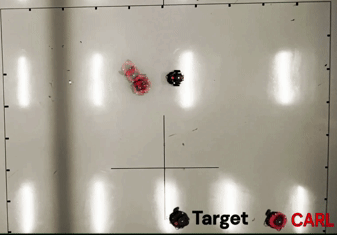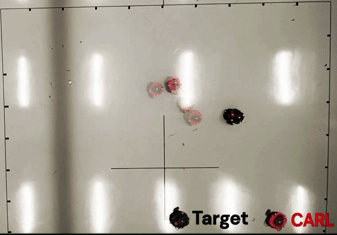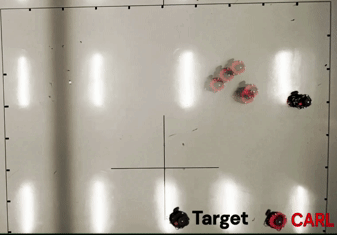
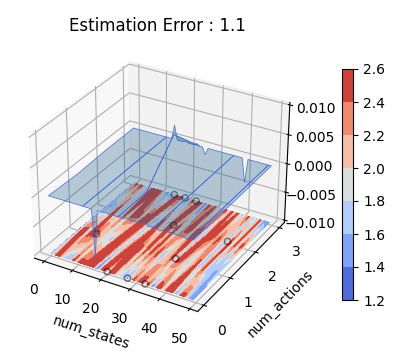
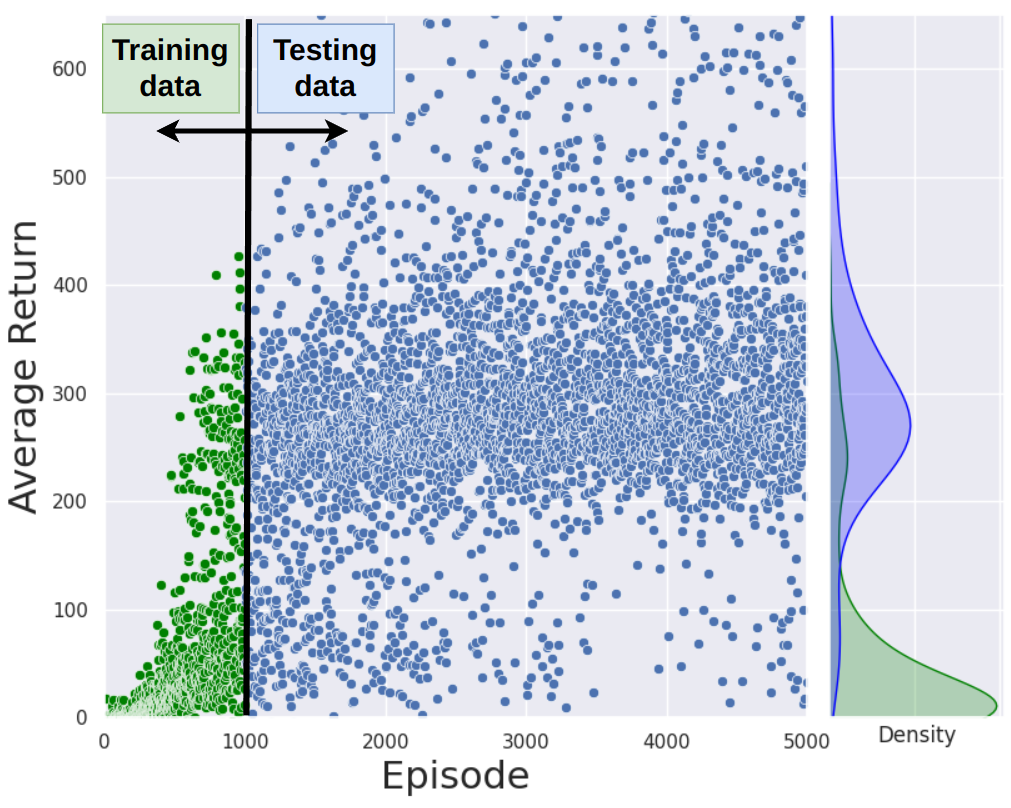
TL;DR: We propose Intrinsic Reward Policy Optimization (IRPO), a novel framework leveraging a surrogate policy gradient to overcome credit assignment and sample inefficiency in sparse-reward environments.
Topics: Hierarchical RL